This is the entry point to a longer technical manual on a setup I have been running for several months: one person using an AI coding assistant as the primary interface to a real physical and operational life. Below: what the system does, why each piece exists, and what I have learned.
The design is measurement over narrative and enforcement over instruction, with defence in depth for anything that touches the physical world. Every safety rule exists because a text instruction failed under pressure, so the architecture has been built up incident by incident rather than designed from the start.
What it looks like from the outside
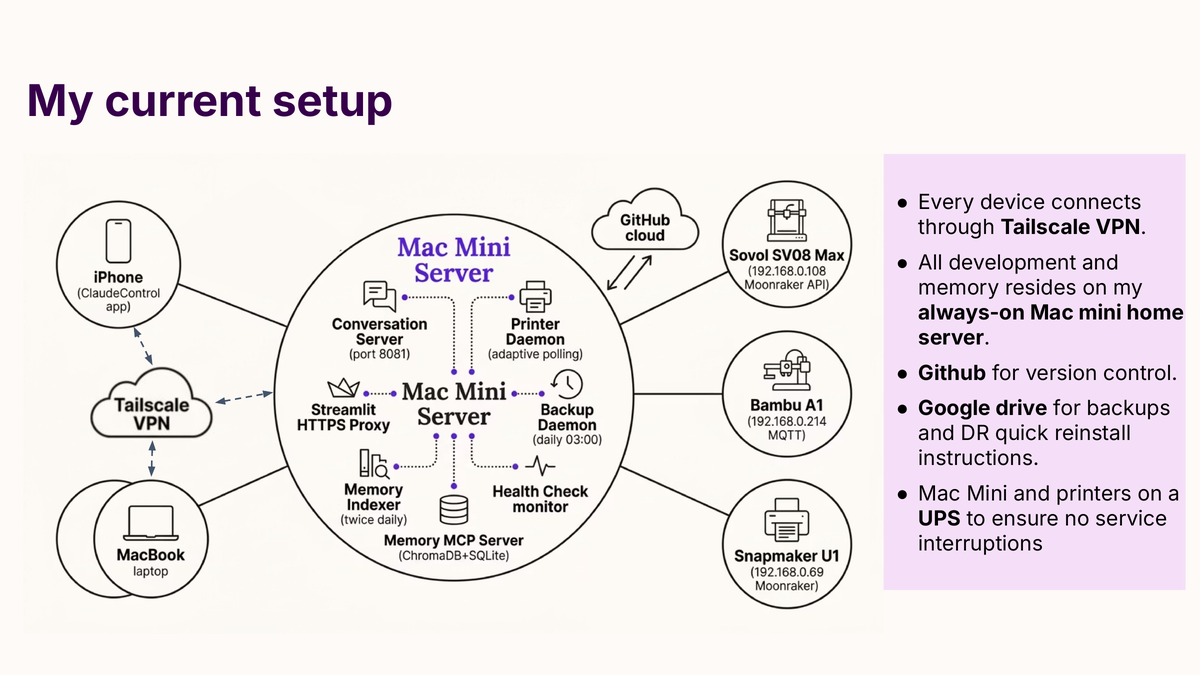
A Mac Mini at home is the always-on server, the MacBook Pro a thin client, my iPhone a third node. All three sit on a Tailscale mesh, giving any device access to any other without VPN configuration.
Persistent services run on the Mac Mini:
- A Flask server brokering Claude Code sessions for my mobile devices.
- An adaptive printer poll (30 seconds during a print, five minutes when idle).
- Daily differential backup to Google Drive.
- OAuth token refresh.
- Weekly sync of school governance documents.
- Credential rotation.
- Scheduled acceptance testing.
- A trend tracker preventing monthly compliance score regression.
- A CI failure poller.
- An observer classifying session failures so I can read the top three every Monday.
Claude Code hooks fire across the session lifecycle to convert text rules into enforcement:
- If a session-start check fails, the session does not start.
- If a printer command is not on the allowlist during a live print, it does not execute.
- If a file write contains a credential pattern, the write is blocked.
A skills directory holds workflows:
/debateruns a three-way review (Claude Opus, Gemini, GPT-5.4) on architectural decisions./reviewruns the lighter pre-commit gate./autonomouslets me say “email me when you are done” and trust the work will complete./dreambrings the day’s memory into the curated layer between sessions.
Skills are versioned in git and deployed through the same pipeline as everything else.
Memory has two tiers, and both exist because each fails where the other succeeds:
- Semantic uses ChromaDB with local embeddings and no external API.
- Keyword uses SQLite’s built-in full-text search engine, FTS5, for exact-match on dates, IP addresses and error strings.
Each indexes around 79,000 chunks from 1,400+ conversations. Curated facts live in structured topic files in their own git repository.
A handful of iOS apps on the phone give me direct touch on the system: a terminal, a governors’ dashboard, a printer control app, a session manager, all on a shared SwiftUI framework. They receive Apple Push Notification service (APNs) push notifications when something interesting happens, including alerts from an “alert-responder” subagent that produces a five-layer root-cause analysis and pushes it with Accept, Reject and Discuss buttons.
What it protects against
A 3D printer is the most expensive worked example. A badly-timed command during a twenty-hour print does not just waste filament; it warps a build plate, jams an extruder, or destroys a part that took a full day to produce. Every layer of the safety architecture came from a real incident. Six defence layers now sit between Claude Code and the printers, and I have not lost a print to automation-induced failure since the last was added.
The wider protection is against failure modes I have repeatedly hit in my own setup: silent failures unnoticed for weeks, helpers that cause more damage than they prevent, shared config files with multiple writers, infrastructure changes based on false assumptions, fixes that do not stick, safety rules ignored under time pressure, rogue processes, memory poisoning, and supply-chain drift in third-party Model Context Protocol (MCP) servers.
Each has a dated incident and a piece of code that now prevents recurrence. They are catalogued in a “lessons learned” file I re-read at every session start. Twenty-three patterns, every one of which has happened to me at least twice.
What I have learned
A few things worth sharing for anyone building similar.
Text rules are a request, not a guard. Every failure mode I have hit started with “the rule was there in markdown and the agent ignored it under pressure.” The fix is not a stronger rule but a layer of enforcement closer to the hardware than the agent can see. Shell-script hooks returning exit code 2 to deny a tool call are the most efficient mechanism I have found.
Context is infrastructure, not a free resource. Anthropic accepts 200,000 tokens of input; the model cannot reliably use them. Liu et al.’s “Lost in the Middle” paper showed that information buried in the middle of a long context is found roughly 25% of the time versus 42% at the end. My own system hit this with a school governors app that loaded a large document corpus per query and was missing meeting minutes buried deep in it. The fix was query-type routing: date-specific queries start with keyword search, open-ended policy questions with semantic search, full-corpus loading is the fallback.
Three-way multi-model review is more valuable for framing diversity than for verdict ensembling. Three models from three labs produce three framings, not three versions of the same answer. Convergence on round zero is weak, because it is often shared training-data bias dressed up as agreement.
Delete, do not add. Every automated “helper” I built to make the system more reliable ended up making it less reliable. The UPS watchdog that paused prints on USB glitches, the auto-speed adjuster that killed prints with mid-flight parameter changes, the power-loss-recovery chain that triggered SAVE_CONFIG during pauses, the printer daemon’s auto-recovery that sent FIRMWARE_RESTART mid-print: I removed all four. Observation is safe, notification is safe, action is not. Any daemon with authority to act on a physical system needs explicit state gates, or removal.
Measurement compounds. The single highest-impact change I can make is not another daemon, skill or MCP server. It is a failure-annotation pipeline that classifies my last week of sessions and tells me on Monday which three failure modes are producing the most rework. The first digest identified that “incomplete-fix” and “env-infra” failures shared a root cause (an image-attachment pipeline issue) I would have treated as two separate problems. Hamel Husain writes that three issues typically cause 60% of problems, and I had not tested whether that was true for me because I had not been looking. It is, and now I am.
Defence in depth is cheaper than it looks. The total code for my six-layer printer safety architecture is small: a markdown rules file, a PreToolUse hook, a couple of Klipper macros, daemon state guards, and one human-approval rule. The investment is trivial against a single destroyed print.
Your pen-test suite probably does not cover AI-specific attack classes. Traditional pen testing looks for injection points, auth bypass and known software vulnerability patterns, but it does not ask “if an attacker planted content in memory, does the model then follow that content as an instruction?”, “is MCP retrieval routed through a system-prompt injection path?”, or “are MCP server packages version-pinned against silent supply-chain drift?” Those are AI-specific test cases. I added a few to my scenarios suite this week.
What is in the long version
The full technical manual covers:
- Infrastructure (Mac Mini + laptop + iPhone on Tailscale)
- Control plane (git-versioned single source of truth)
- Conversation server (Flask daemon brokering mobile access)
- Memory system (dual-tier ChromaDB + FTS5)
- Context management (the measurement-first approach after the governors app failure)
- Hooks and enforcement
- Printer safety (the six-layer architecture)
- Multi-model review (/debate, /review, /autonomous)
- Security posture
- Automated security testing and penetration testing
- The daemon layer
- MCP integrations
- The skills directory
- Automated maintenance
- The governors app as a case study in context management
- The lessons-learned framework, including the root-cause-analysis protocol
Each section includes dated incidents, the fix applied, and the technical control that now prevents recurrence. A few sections have companion posts:
- “Six layers of defence for an AI agent over a 3D printer” covers the printer safety architecture, with every Klipper macro and hook script.
- “Five things I built to help my AI agent that I had to remove” covers the removed automations, the incidents that triggered removal, and the pattern I now apply.
- “Three-way AI model debate as a pre-commit gate” covers /debate with receipts and the one confidence trap the protocol produced.
If you are building something similar and find places where this is wrong, or where the pattern does not generalise, I would like to hear. Contact details are on the about page. The code will be in public repositories when those are up; the prompts and hooks are small enough to copy by hand.