Marketing list requests of this shape often take an analyst several days: companies of a specific kind, filtered by financial and operational characteristics, pulling from sources that did not share a schema. I had an hour.
The constraints were detailed. Companies in a specific sector. Revenue band within a defined range. Filed accounts recent enough to be informative. Signals from public materials such as trading statements and annual reports, which could only be parsed with optical character recognition because the filings were scanned PDFs. Then ranked by fit to an explicit profile.
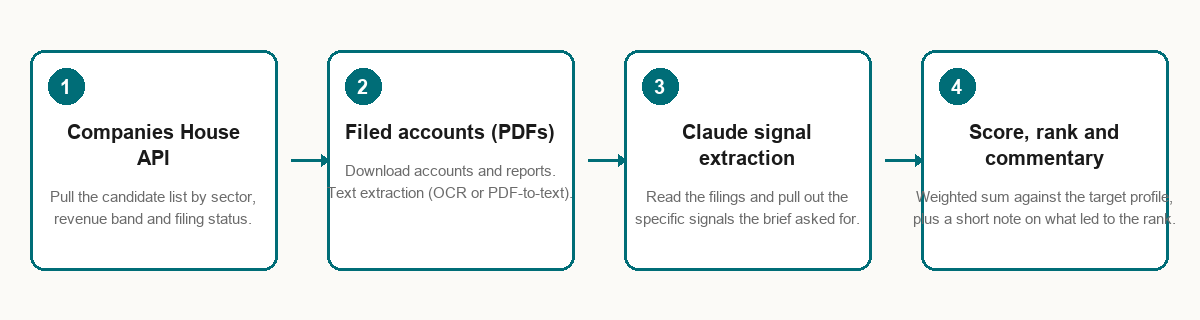
One source (Companies House) in two formats (API metadata and scanned PDF filings), then a sorting rule on top. In a previous world I would have described this to an analyst and waited a couple of days. This time I opened a Claude Code session and talked it through what I wanted.
What the session did
In one session, with me describing what I wanted and watching outputs as they arrived, the following got built.
A small script queried the Companies House API for companies in the right sector, size band and filing status. The API is public and the parameters are well-documented; Claude wrote the query, pagination loop and parser. Output: candidates with company numbers and registered addresses.
A second script pulled the most recent filed accounts for each candidate. Some accounts are structured text PDFs, some scanned images, so the script used a Python OCR library for the scanned ones and a PDF-to-text library for the structured ones.
A third script used Claude to read the extracted filings and pull out the specific financial and operational signals I needed.
A final script scored each company against the target profile using a weighted sum, sorted the output, and added a short piece of commentary per company explaining which parts of the filed accounts had led to the conclusion.
Total wall time from first prompt to spreadsheet was under an hour, most of it spent reading intermediate outputs to catch errors, not writing code.
What this was not
It was not a production pipeline. No test coverage, minimal error handling, no logging, no retry logic. A scaffold. If the business wanted to run it weekly an engineer would need to harden it, but the feedback from the client was positive. The test file I produced manually was exactly the kinds of merchants they wanted to target.
The small insight
The pipeline crossed several formats in sequence: the Companies House API for metadata, the scanned PDF filings via OCR, the extracted text fed back to Claude for signal extraction, and the resulting table scored against the profile. Each step is straightforward on its own. What took an hour here would have taken considerably longer through the usual channels, not because any piece is hard, but because the cost of stitching the steps together is usually greater than the cost of the work inside each step.
Agents lower that stitching cost to almost zero. The same session that wrote the Companies House call wrote the OCR extraction, the Claude prompting and the ranking, with no handover, specification or version mismatch.